Welcome to the annual (or bi-annual if we're lucky) blog post, and happy belated new years!
I'm gonna be honest, I don't care much for AI, but it'd be silly not to use it at least sparingly, but one concern I've always had is privacy, everything you do in that chat GPT web page is stored and used to train the model further.
Granted that makes sense, because you're getting a free experience, but even when you do pay, the same occurs, but now that we have deepseek, can we run it locally and keep all our data to ourselves?
If you've been living under a rock, the Deepseek R1 is an open source generative AI model that was released in January 2025, it is revolutionary because it rivals GPT o1, is free, and operates at a fraction of the cost.
Anyway let's get it on our machines.
Ollama
We're going to be using ollama, which is an app used to manage local LLMs on your machine.
Let's get it installed, then we're going to install our model.
here's a link to the deepseek model on there.
Now there are a bunch of models, obviously we can't run the full sized version on any commercial hardware, so we're going to pick on something our own size.
Other options are quantized models, that they've been reduced in precision, and consequently in size and hardware requirements, we have a bunch of quantized versions, they are:
- DeepSeek-R1-Distill-Qwen-1.5B
- DeepSeek-R1-Distill-Qwen-7B
- DeepSeek-R1-Distill-Llama-8B
- DeepSeek-R1-Distill-Qwen-14B
- DeepSeek-R1-Distill-Qwen-32B
- DeepSeek-R1-Distill-Llama-70B
The B refers to billion parameters, more parameters is more accuracy and more resources.
There are a lot of limiting factors when it comes to choosing which model, but mainly its ram, the entire model will be in our ram, so if we don't have enough it won't start, or will crash.
I fiddled around and found that I can run the 14B version with some ram left over, so we're going with that one.
Downloading the model
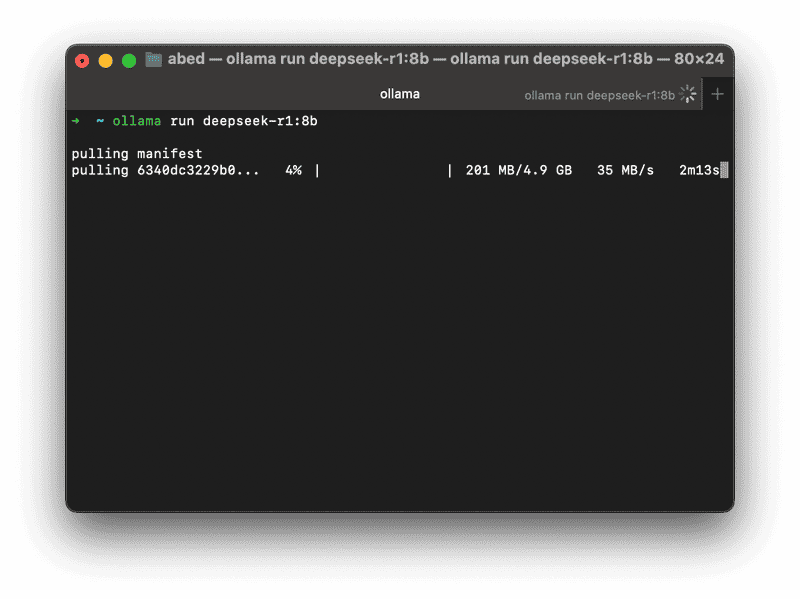
This is going to take a while, so start the download and go do something productive, like writing a blog post about it.
ollama run deepseek-r1:14b
Interacting with the model
After the download, you'll have the same terminal open as a chat with deepseek, let's ask some hard hitting questions:
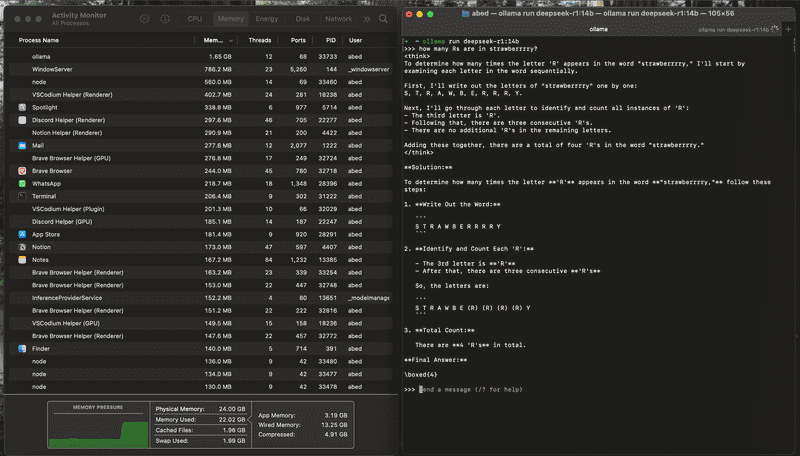
Runs good, but wrong answer, spectacular.
Web UI
Now that deepseek is running in the terminal (which is good enough for me), We have the option of running it in a chat GPT esq UI, and there are a few ways to achieve that:
I am going to use Open WebUI for this example, it's pretty simple to get up and running.
If your python version is < 3.11, you need to download that first
brew install python@3.11 # optional
pip install open-webui
open-webui serveThen we can navigate to http://0.0.0.0:8080
Review & Reflection
This is pretty exciting, and my first time ever running an AI on my local machine, however in its quantized form, its nowhere near a replacement to chat GPT or the full size deepseek.
The problem is that it takes a long time to respond, and the responses are not the best, I tried asking it a few questions about tech stuff, health stuff etc, and the responses were either generic or wrong in some cases.
Also since deepseek thinks, it takes some time to start generating responses, but I have to say seeing the thinking and reasoning is fascinating.
The 8B parameter version is considerably faster, but also less accurate, but I didn't exactly test them both extensively to find out the shortcomings of the smaller model, maybe go for the 8b version if you have a machine like mine.
In short will it replace my usual AI tools? probably not, but then again I am running this from a laptop, and I'm excited to have experienced hosting an LLM, and this was pretty fun to run.
If you have a more powerful machine, maybe the bigger models could appease some of the problems I faced 🤔.